
Binnen iedere zorginstelling (of bedrijf) worden veel gegevens vastgelegd, bewerkt en gebruikt. Gegevens op zich zijn nog geen informatie. Bovendien worden er vrijwel altijd meerdere applicaties gebruikt – al dan niet gekoppeld – waarin onderling samenhangende gegevens worden vastgelegd. Zo komen cliënten en medewerkers bijna altijd in meerdere applicaties voor.
Een informatiemodel is een inhoudelijk
hulpmiddel om van de gegevens binnen
de organisatie informatie te maken.
Als organisatie wil je zelf bepalen wat de relatie is tussen al die gegevensobjecten. Bijvoorbeeld als er managementinformatie wordt gemaakt die een samenvoeging is uit verschillende bronnen (datawarehouse / BI-tool). Los van het technische vraagstuk (om verschillende databases op juiste wijze één datawarehouse te laten “vullen”), moet je zelf de vraag stellen wat je bedoelt met bepaalde termen.
Het informatiemodel bestaat uit een grafische weergave van alle objecten en hun onderlinge verhouding en een tekstuele toelichten daarop, die zowel definities bevat als de bedrijfsregels die erop van toepassing zijn. Hiermee vormt het informatiemodel een belangrijke basis voor de beschrijving van de informatie-architectuur in zijn geheel.
Definities
Een voorbeeld dat keer op keer opduikt is het begrip productie (wat je verder ook voor gevoel krijgt bij dit woord…), wat feitelijk de verzameling verrichtingen is, terwijl als er sprake is van productiviteit de verhouding van een deelverzameling van tijdsbestedingen tot het totaal beoordeeld wordt. Deze deelverzameling kan naast de (directe, cliëntgerelateerde) tijdsbesteding worden uitgebreid met andere typen bestedingen, zoals opleidingen en dergelijke. Om een betrouwbaar cijfer te produceren moet de definitie glashelder zijn en vervolgens te worden doorvertaald in technische zin – bij het bepalen welke gegevens uit welke bron moeten worden gehaald, hoe die zich tot elkaar verhouden (welke uursoorten zijn wel productief en welke niet?), welke gegevensverzamelingen moeten worden gehanteerd (om bijvoorbeeld te kunnen “drillen” – je begint met het totale cijfer van de organisatie en wilt dan doorklikken om te zien waar er eventueel probleemclusters / -teams zijn, etc.).
Een ander voorbeeld dat altijd opduikt is verzuim of ziekte. Valt zwangerschap daar nu wel of niet onder? En wat doen we qua weergave in de cijfers met langdurig zieken? Hoe zit het met in- en uitleen?
Objecten die in applicaties worden vastgelegd, dienen daarom eenduidig gedefinieerd te worden. Hiervoor gebruiken we een informatiemodel. In dit “semantische” model worden diverse informatie-eenheden benoemd die een rol spelen in de zorg en behandeling, bij sturing van de organisatie en verantwoording over bijvoorbeeld productie en productiviteit.
Het opstellen van een informatiemodel
maakt vaak duidelijk dat binnen een
organisatie verschillende definities
voor op het oog dezelfde objecten worden gebruikt.
Op basis van dit model kan je als organisatie zelf een uniforme interpretatie ontwikkelen, die voorkomt dat gegevens uit hun context worden gehaald of op dubbelzinnige wijze worden gepresenteerd. Op het moment dat er een discussie ontstaat over de definitie van begrippen kan het model de discussie laten richten op het werkelijke ‘probleem’, zodat zo snel mogelijk de inhoud van de gegevens kan worden gesproken en de interpretatie eenduidig is en geen onderwerp van discussie. Wijzigingen in interpretatie of afspraken hebben op het model zelf geen invloed, uitsluitend op groepering van gegevens met bepaalde kenmerken.
De praktijk wijst uit dat bij het opstellen van een informatiemodel duidelijk wordt dat binnen de organisatie verschillende definities worden gehanteerd. Dat is logisch, want iemand van HR “kijkt” heel anders naar alle gegevens rondom de medewerker dan bijvoorbeeld iemand die verantwoordelijk is voor de roosters van medewerkers. Alleen de discussie die ontstaat bij het ontwikkelen van het eigen informatiemodel is vaak heel verhelderend naar elkaar toe. Soms blijkt er letterlijk jarenlang langs elkaar heen te zijn gecommuniceerd, puur omdat impliciete definities verschilden. Wat voorbeelden van vragen die dan vaak opdoemen:
- Hoe tellen we onze cliënten? Wat is een “cliënt in zorg”? Wat als een cliënt voor kortere of langere tijd in het ziekenhuis ligt?
- Hoe verhouden het zorg(leef)plan en het behandelplan zich tot elkaar (in termen van informatie)?
- Hoe zit het met de types tijdsbesteding in relatie tot salariscomponenten?
- Is een uitzendkracht of een zzp (in de zin van zelfstandige zonder personeel) ook een medewerker? Hoe bepalen we een zuiver beeld van de productiviteit van een team waar uitzendkrachten werken?
- Hoe zit het met onderaannemerschap (wij leveren zorg bij de cliënt van een andere instelling of andersom)?
- En bij alles geldt: hoe zit dit “in de tijd”? Het gaat immers niet om het beeld van de organisatie op één gegeven moment, maar over een jaar of een deel daarvan. Hoe tel je dan je cliënten of medewerkers?
Objecten en attributen
De kern van het informatiemodel zijn de objecten in hun onderlinge samenhang. Ieder object heeft attributen (eigenschappen). Denk aan het object “medewerker” met als attributen “naam”, “adres”, “geslacht”, “geboortedatum”, etc. Er is geen wet van de meden en perzen waar het omslagpunt ligt wanneer iets een object is en wanneer een attribuut.
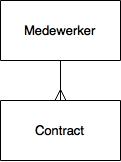
Voorbeeld van objecten en hun relatie
In het grafische deel van het informatiemodel wordt elk object omsloten door een vierkant blokje. De relatie tussen de elementen wordt met een harkje weergegeven. De richting van het harkje geeft aan hoe de “informatie-technische” verhouding is tussen de elementen. We spreken dan van 1:1 of 1:n of n:1 of n:n. Een voorbeeld hiervan is de relatie tussen medewerker en contract. Een medewerker kan meerdere contracten hebben, maar een contract hoort altijd maar bij één medewerker; we noemen een dergelijke relatie 1:n. De hark heeft dan de vertakking bij contract.
Dimensies
Het model kent een opdeling van informatie per dimensie. Een dimensie is het gezichtspunt of de invalshoek van waaruit de gegevens worden bekeken. De meest gebruikte dimensies zijn: cliënt, zorg / behandeling (inhoudelijk), medewerker, organisatie en financiën.
Bij het beschouwen van informatie zijn het namelijk vaak dezelfde gegevens die in verschillende vormen terugkomen en bekeken kunnen worden. De urenregistratie bijvoorbeeld is één grote vergaarbak waarbij deze uren telkens vanuit een ander gezichtspunt bekeken kunnen worden. De ene keer in relatie tot de medewerker, waarbij aspecten als kosten, arbeidsvoorwaarden en dergelijke relevant zijn, de andere keer in relatie tot de cliënt, waarbij aspecten als product, tarief, financiering en dergelijke relevant zijn. Maar het gaat wel om dezelfde uren! Om verwarring in de vraagstelling te voorkomen en informatie ondubbelzinnig te kunnen presenteren (dus geen verkeerde interpretaties mogelijk te maken), kan een informatiemodel uitstekend helpen.
Stappen na het informatiemodel
Zoals gezegd is het informatiemodel een belangrijke basis, maar zeker niet het eindpunt. De noodzaak de informatie-architectuur in de volle breedte te beschrijven en onderhouden wordt gelukkig door steeds meer instellingen onderkend. Op basis van het informatiemodel kunnen de volgende stappen worden gezet:
- Beschrijven applicatie-architectuur: hierbij kan de relatie worden beschreven tussen de “overall” informatie-architectuur en iedere applicatie en koppelingen daartussen (ook handmatige!). In feite wordt er een vertaling gemaakt van de terminologie van de organisatie naar de terminologie in de applicatie – zowel wat er op het scherm staat als in de database. Dit helpt enorm bij het beheren van koppelingen.
Veel aandacht dient te worden besteed aan verschillen tussen hoe de organisatie tegen haar gegevensobjecten aankijkt en hoe dit is ontworpen door leveranciers van applicaties. Hierin zullen verschillen zitten. Mogelijk moeten de bedrijfsregels worden doorvertaald naar procesafspraken (bijvoorbeeld als het technisch mogelijk is een 1:n relatie te leggen tussen objecten, maar de organisatie kiest voor een 1:1 relatie). Zeker ook bij het genereren van managementinformatie is het van belang precies te weten waar deze verschillen zitten en hoe dit is opgelost. - Beschrijven autorisatiestructuur: gegevens kunnen worden aangemaakt, gemuteerd en verwijderd. Per object (en eventueel hun attributen) kan worden bepaald welke functie of rol welke autorisatie krijgt. Dit kan vervolgens worden doorvertaald per applicatie. Idealiter kan vanuit de matrix binnen het informatiemodel worden gewerkt, maar in de praktijk zijn er nog maar weinig applicaties die kunnen werken met autorisaties die niet rechtstreeks in betreffende applicatie is ingevoerd.
- Beschrijven procesarchitectuur: alle gegevens worden verzameld, ingevoerd en bewerkt binnen processen. Deze processen hebben ook weer een onderlinge relatie. Zo maakt HR de medewerker aan in hun applicatie en zal die medewerker op een vastgesteld punt in de tijd beschikbaar moeten zijn om te kunnen worden ingeroosterd – meestal in een andere applicatie. Los van de “diepte” beschrijvingen van de processen zelf, dienen de hoofdprocessen en vooral hun samenhang in een procesarchitectuur te worden beschreven.
Tot slot
Het opstellen van een informatiemodel is een flinke klus, vaak vooral omdat duidelijk wordt dat er binnen de organisatie toch verschillen zijn tussen de definities die worden gehanteerd voor op het oog zo eenduidige objecten. Toch is het een inspanning die de moeite waard is, want het beheer van de informatievoorziening in de breedte wordt er veel eenvoudiger door. Maar… het vraagt wel een ijzeren discipline dit goed te beheren. Vooral als de doorvertaling naar applicatie-architectuur, autorisatie en procesarchitectuur is gemaakt. Zonder die discipline is dit alles in een oogwenk achterhaald en heb je er dus eigenlijk weinig aan.
Dus: bezint eer ge begint! In mijn ogen is het een randvoorwaarde voor een goed beheer van de informatievoorziening, dus ik adviseer nadrukkelijk deze stappen te zetten en te borgen, maar het kost tijd en vraagt dus discipline om het ook echt goed te doen.